책 소개
제목 : 스파크 완벽 가이드
저자 : 빌 체임버스, 마테이 자하리아
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=175546079
Part 1. 빅데이터와 스파크 간단히 살펴보기
Chapter 1. 아파치 스파크란
- 아파치 스파크
- 통합 컴퓨팅 엔진
- 클러스터 환경에서 데이터를 병렬로 처리하는 라이브러리 집합 (병렬 처리 오픈소스 엔진)
- 4가지 언어 지원
- python
- java
- scala
- R
- 단일 노트북 환경 ~ 수천 대의 서버로 구성된 클러스터까지 다양한 환경에서 실행 가능
- 스파크 기능 구성 (스파크가 제공하는 전체 컴포넌트와 라이브러리)
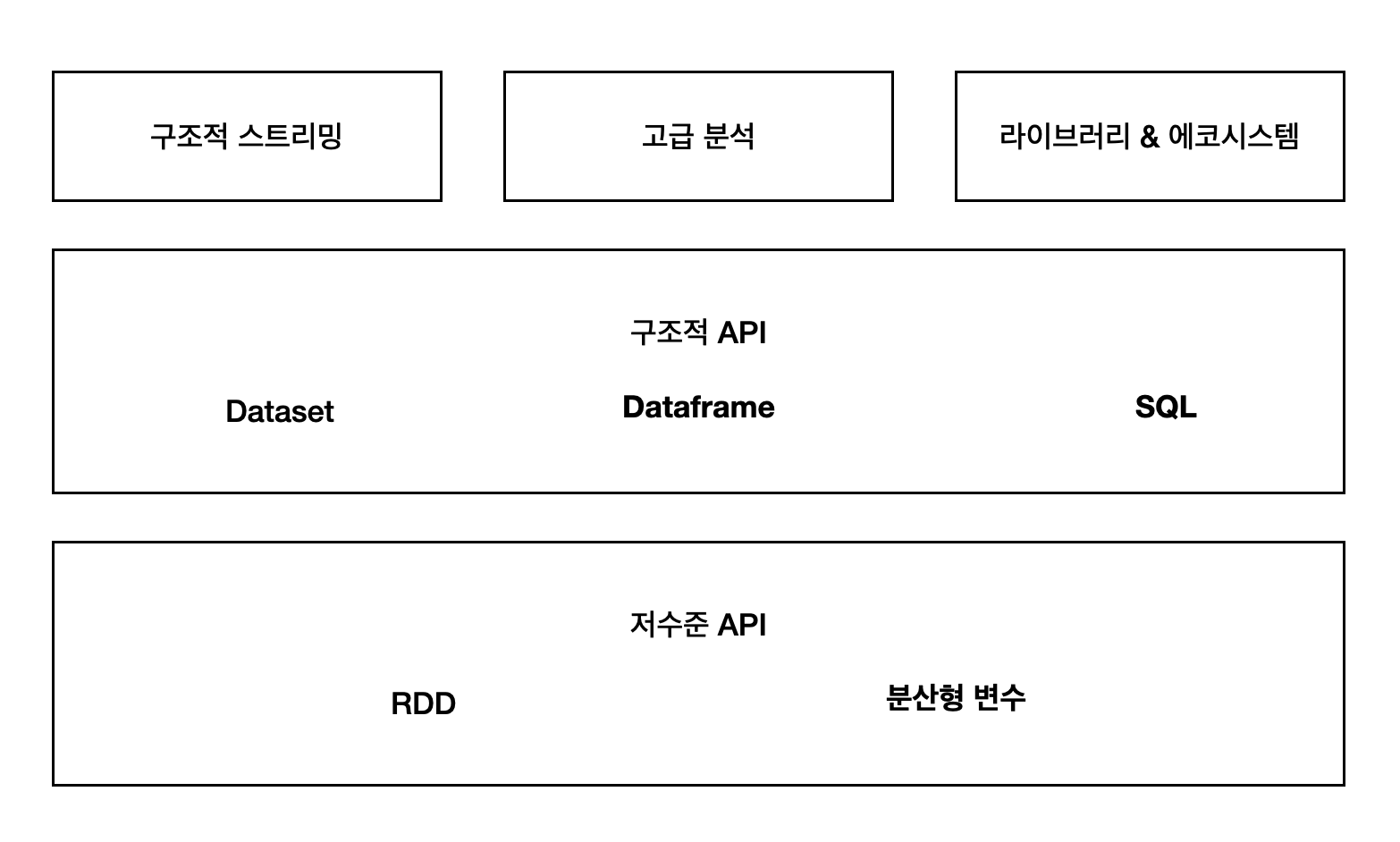
1.1 아파치 스파크의 철학
- 통합 (unified)
- 스파크의 핵심 목표: 빅데이터 애플리케이션 개발에 필요한 통합 플랫폼 제공
- 통합 : 간단한 데이터 읽기 ~ SQL 처리, 머신러닝, 스트림 처리까지 다양한 데이터 분석 작업을 같은 연산 엔진과 일관성 있는 API로 수행 가능
- 스파크의 통합 특성을 통해 기존의 데이터 분석 작업을 더 쉽고 효율적으로 수행 가능
- 일관성 있는 조합형 API를 이용해 애플리케이션을 만들거나, 직접 스파크 기반 라이브러리 생성
- 스파크는 데이터 분석계에서 최초로 통합 엔진을 제공하는 오픈소스
- 전에는 사용자가 다양한 API와 시스템을 직접 조합해서 애플리케이션 만들어 내야 했음
- 컴퓨팅 엔진
- 스파크는 저장소 시스템의 데이터를 연산하는 역할만 수행 (영구 저장소 역할은 수행 X)
- 통합이라는 관점을 중시하기 때문
- 대신 Azure Storage, S3, Apache Hadoop(분산 파일 시스템), Apache Cassandra (키/값 저장소), Apache Kafka (메시지 전달 서비스) 등의 저장소 지원
- 스파크는 내부에 데이터를 오랜 시간 저장하지 않고 특정 저장소 시스템을 선호하지 않음
- 실제로 대부분의 데이터는 여러 저장소 시스템에 혼재되어 저장 되기 떄문
- 데이터 저장 위치에 상관없이 처리에 집중하도록 만들어짐
- 사용자 API도 서로 다른 저장소 시스템을 매우 유사하게 볼 수 있도록 만들어짐
- 애플리케이션은 데이터가 저장된 위치를 신경쓰지 않아도 됨
- 스파크는 연산 기능에 초점
- 하둡은 하둡 파일 시스템과 컴퓨팅 시스템(맵리듀스) 보유 → 하둡과 스파크는 매우 밀접하게 연관됨
- 하둡에서 다른 저장소의 데이터에 접근하고 싶을 때 스파크 사용하면 쉬움
- 스파크는 저장소 시스템의 데이터를 연산하는 역할만 수행 (영구 저장소 역할은 수행 X)
- 라이브러리
- 스파크는 데이터 분석 작업에 필요한 통합 API 제공 (통합 엔진 기반의 자체 라이브러리)
- 오픈소스 라이브러리도 사용 가능
- SQL과 구조화 된 데이터를 제공하는 SparkSQL, 머신러닝을 지원하는 MLlib, 스트림 처리 기능을 제공하는 스파크 스트리밍, 구조적 스트리밍, 그래프 분석 엔진 GraphX 라이브러리 제공
- 다양한 저장소 시스템을 위한 커넥터도 제공
- https://docs.snowflake.com/ko/user-guide/spark-connector-overview.html
- connector : 다른 데이터 소스를 spark와 연결 (DB 라이브러리 + DB 커넥터 라이브러리 함께 사용)
- 머신러닝을 위한 알고리즘 등 제공
- 전체 라이브러리 목록: spark-packages.org 에서 확인
1.2 스파크의 등장 배경
- 컴퓨터 애플리케이션과 하드웨어의 바탕을 이루는 경제적 요인이 변화
- 프로세서의 성능 향상으로 컴퓨터가 빨라지고, 애플리케이션도 빨리 실행됨
- 대규모 애플리케이션도 프로세서가 빨라지면서 만들어지고 이 때 시스템은 단일 프로세서에서만 실행되도록 설계 (하드웨어 발전에 의존)
- 2005년 경에 하드웨어의 성능 향상 멈춤 → 병렬 CPU 코어 더 많이 추가하는 방향으로 변경
- 애플리케이션의 성능 향상을 위해 병렬 처리 필요해짐 → 스파크가 병렬 처리 지원
- 데이터 수집 비용도 감소 추세
- 다양한 데이터를 저렴하게 수집할 수 있지만 데이터는 클러스터에서 처리해야 할 만큼 거대해짐
- 클러스터: 각기 다른 서버들을 하나로 묶어서 하나의 시스템 같이 동작하게 함으로써 클라이언트들에게 고가용성의 서비스 제공 (클러스터로 묶인 한 시스템에 장애가 발생하면, 정보의 제공 포인트는 클러스터로 묶인 다른 정상 서버로 이동)
- 소프트웨어는 성능 향상에 한계가 생기고 스파크가 등장 (더 많은 데이터를 저렴하게 적재)
- 다양한 데이터를 저렴하게 수집할 수 있지만 데이터는 클러스터에서 처리해야 할 만큼 거대해짐
1.3 스파크의 역사
- 2009년 UC 버클리 대학교에서 스파크 연구 프로젝트로 시작 (AMPLab)
- <Spark: Cluster Computing with Working Sets> 논문으로 세상에 나옴
- 당시 하둡 맵리듀스는 수천 개의 노드로 구성된 클러스터에서 병렬로 데이터를 처리하는 최초의 오픈소스 시스템 & 클러스터 환경을 위한 병렬 프로그래밍 엔진
- AMPLab은 맵리듀스 사용을 바탕으로 문제점을 정리해 더 범용적인 컴퓨팅 플랫폼 설계
- 하둡 사용자 더 연구해서 2가지 깨달음 얻음
- 1. 클러스터 컴퓨팅이 엄청난 잠재력을 가짐
- 2. 맵리듀스 엔진을 사용하는 대규모 애플리케이션의 난이도와 효율성
- 전통적인 머신러닝 알고리즘은 데이터를 10-20회 가량 처리 but 맵리듀스로 처리하려면 단계별로 맵리듀스 잡 개발 → 클러스터에서 각각 실행 → 매번 처음부터 데이터 읽어야 함
- 처음 스파크는 배치 애플리케이션만 지원
- 이후에 대화형 데이터 분석, 비정형 쿼리 등 강력한 기능 제공
- 처음에는 스칼라 인터프리터를 단순히 스파크에 접목해서 수백 개의 노드에서 쿼리 실행 (대화형 데이터 분석 시스템)
→ 유저들이 Shark 개발 (스파크에서 대화형 SQL 실행) - 이후 MLlib, 스파크 스트리밍, GraphX와 같은 다양한 라이브러리 개발 (표준 라이브러리 형태의 구현 방식 유지.. 현재까지도)
- 스파크의 뛰어난 호환성 덕분에 처음으로 같은 엔진을 이용해 여러 처리 유형을 결합한 빅데이터 애플리케이션 개발 가능
- AMPLab은 스파크가 특정 업체에 종속되는 것을 막기 위해 아파치 재단에 기부 → 이후 데이터브릭스 설립
- 아파치 소프트웨어 재단 (Apache Software Foundation, ASF)
- 아파치 소프트웨어 프로젝트를 지원하는 비영리 재단
- 개발자들의 분산 커뮤니티
- 그들이 개발하고 있는 소프트웨어는 아파치 라이선스 조항 아래 배포되고 자유 소프트웨어/오픈 소스 소프트웨어이어야 한다.
- 아파치 소프트웨어 재단 (Apache Software Foundation, ASF)
- 개선을 위해 스파크 팀은 효율적인 API 설계
- 1. 여러 단계로 이루어진 애플리케이션을 간결하게 개발하도록 함수형 프로그래밍 기반의 API 설계 (조합형 API)
- 초기 버전은 함수형 연산 (자바 객체로 이루어진 컬렉션에 맵이나 리듀스 같은 병렬 연산 수행) API
- 스파크 1.0 버전부터는 구조화된 데이터를 기반으로 동작하는 신규 API (스파트SQL) 추가 (자바의 인메모리 데이터 표현 방식에 종속되지 않음)
- 스파크 SQL은 데이터 포맷, 코드를 이해하는 라이브러리 + API를 이용해 새롭고 강력한 최적화 기능 제공
- 이후 dataframe, 머신러닝 파이프라인, 자동 최적화를 수행하는 구조적 스트리밍 등 구조체 기반의 신규 API 추가
- 2. 연산 단계 사이에서 메모리에 저장된 데이터를 효율적으로 공유할 수 있는 새로운 엔진 기반의 API 구현
- 1. 여러 단계로 이루어진 애플리케이션을 간결하게 개발하도록 함수형 프로그래밍 기반의 API 설계 (조합형 API)

1.4 스파크의 현재와 미래
- 빅데이터 분석을 수행하는 기업의 핵심 기술이 될 것
1.5 스파크 실행하기
- 스파크 시작하는 방법
- 1. 로컬에서 설치해서 실행
- 2. 데이터브릭스 커뮤니티 버전 실행
1) 로컬 환경에 스파크 내려받기
- java 설치 되어 있어야 함 (java로 확인)
- 스파크 공식 홈페이지 → Pre-built for Hadoop 2.7 and later → Download
2) 하둡 클러스터용 스파크 내려받기 (나중에)
- pip install pyspark... 다음에 진행
3) 소스에서 직접 필드하기
- 소스를 이용해 스파크를 build 하고 설정할 수 있음
cd /Downloads
tar -xf spark-2.2.0-bin-hadoop2.7.tgz
cd spark-2.2.0-bin-hadoop2.7.tgz- 스파크 소스 코드 확인할 때 사용
1.5.2 스파크 대화형 콘솔 실행하기
- 파이썬 콘솔
./bin/pysparkspark- SparkSession 객체 출력
- 스칼라 콘솔
./bin/spark-shellspark- SparkSession 객체 출력
- SQL 콘솔
./bin/spark-sql
1.5.3 클라우드에서 스파크 실행
- 데이터브릭스 커뮤니티 판
1.5.4 데이터 소스
- 역자의 깃허브 코드 저장소
- https://bit.ly/2QKoyM6
1.5.5 도커에서 실행하기
- $ docker pull rheor108/spark_the_definitive_guide_practice
- $ docker run -p 8080:8080 -p 4040:4040 rheor108/spark_the_definitive_guide_practice
- http://localhost:8080 (재플린 접속)
'TechBooks' 카테고리의 다른 글
| [Spark] 스파크 완벽 가이드 #3장 (0) | 2022.05.06 |
|---|---|
| [Spark] 스파크 완벽 가이드 #2장 (0) | 2022.05.06 |
| [Python] 파이썬 코딩의 기술 1장 (0) | 2022.03.06 |
| [Programming] 객체지향의 사실과 오해 #7장 (0) | 2020.07.16 |
| [Programming] 객체지향의 사실과 오해 #6장 (0) | 2020.07.14 |




댓글